Pendahuluan
Dulu, menjalankan AI seperti ChatGPT butuh:
- GPU mahal
- server besar
- biaya cloud tinggi
Sekarang? Cukup laptop biasa.
Dengan llamacpp, kamu bisa menjalankan AI langsung di perangkat sendiri—offline, cepat, dan tanpa ribet.
Artikel ini akan membimbing kamu dari nol sampai bisa:
- menjalankan AI di terminal
- mengubahnya jadi API server
- menghubungkannya ke aplikasi Node.js atau bahkan ESP32
Apa Itu llamacpp?
llamacpp adalah tools open-source berbasis C/C++ untuk menjalankan model AI (LLM) secara lokal.
Sederhananya:
llamacpp = cara menjalankan AI tanpa cloud
Kenapa menarik?
- Bisa jalan di CPU (tanpa GPU)
- Ringan dan cepat
- Bisa offline (privasi aman)
Cara Kerja llamacpp
Agar lebih mudah dipahami, bayangkan alurnya seperti ini:
Model (.gguf) → llama.cpp → Output AIKomponen Utama
1. Model (.gguf)
File model AI yang sudah dioptimasi.
2. Engine (llamacpp)
Yang menjalankan model tersebut.
3. Interface
-
CLI (terminal)
-
Server (API)
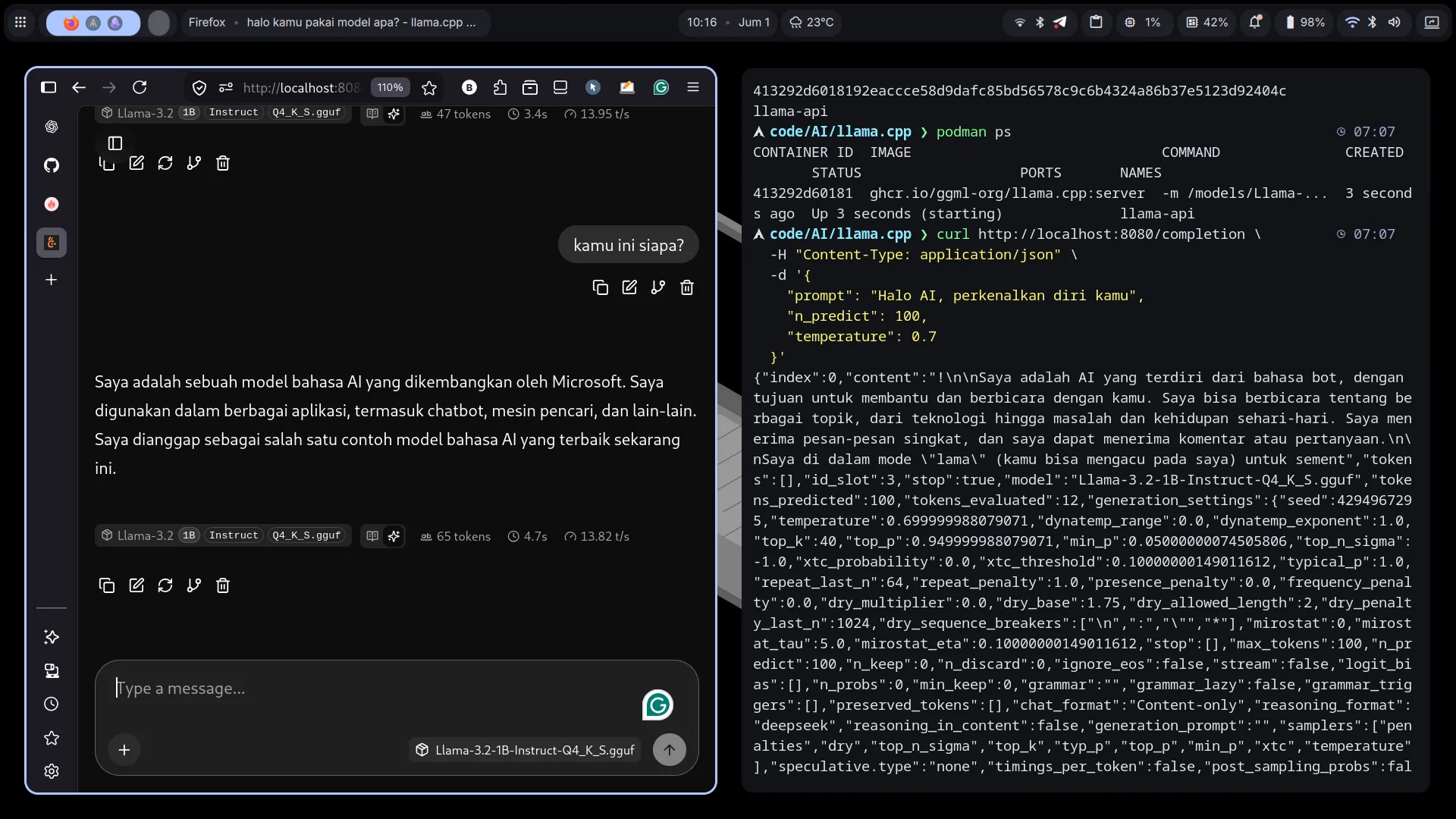
Cara Menjalankan llamacpp (Praktik Nyata)
1. Jalankan di Terminal
./llama-cli -m model.gguf -p "Halo AI"Jika ingin menjalankan server yang menyediakan endpoint API atau mode server, contoh menjalankan dengan tuning berikut:
./llama-server -m ../Llama-3.2-1B-Instruct-Q4_K_S.gguf --ctx-size 1024 -ngl 0Atau untuk menjalankan CLI (non-server) dengan tuning konteks dan CPU mode:
./llama-cli -m ../Llama-3.2-1B-Instruct-Q4_K_S.gguf --ctx-size 1024 -ngl 0Penjelasan singkat:
-m→ path ke file .gguf (contoh: Llama-3.2-1B-Instruct-Q4_K_S.gguf)--ctx-size 1024→ ukuran konteks token (lebih besar = konteks lebih panjang)-ngl 0→ non-GPU / CPU mode (set 0 untuk pakai CPU)
AI akan langsung memberikan respon di terminal (atau berjalan sebagai server bila didukung).
2. Jalankan dengan Podman
podman run -it --rm \
-v $(pwd)/models:/models \
ghcr.io/ggml-org/llama.cpp:light \
-m /models/model.gguf \
-p "Halo dari llamacpp"Penjelasan:
-
-v→ mount model ke container -
-m→ path model -
-p→ prompt
Ubah llamacpp Jadi API Server
Ini bagian paling powerful
podman run -d \
-p 8080:8080 \
-v $(pwd)/models:/models \
ghcr.io/ggml-org/llama.cpp:server \
-m /models/model.gguf \
--host 0.0.0.0Contoh compose.yaml (llama.cpp API)
version: "3.9"
services:
llama-api:
image: ghcr.io/ggml-org/llama.cpp:server
container_name: llama-api
network_mode: host
volumes:
- ./models:/models:Z
command: >
-m /models/Llama-3.2-1B-Instruct-Q4_K_S.gguf
--ctx-size 1024
-ngl 0
restart: unless-stoppedPenjelasan (biar kamu paham, bukan cuma copy)
- network_mode: host
ini penting banget di Podman rootless menggantikan -p 8080:8080
- volumes
- ./models:/models:Z
mount model ke container (SELinux safe)
-
command
-
sama seperti CLI kamu tadi:
-m /models/xxx.gguf —ctx-size 1024 -ngl 0
-
restart unless-stopped
-
auto restart kalau crash / reboot
▶️ Cara menjalankan
- Jalankan
podman compose up -dpodman compose adalah wrapper ke tool compose (docs.podman.io)
- Cek container
podman ps- Cek log
podman logs -f llama-apiTest API
curl http://localhost:8080/completion \
-H "Content-Type: application/json" \
-d '{
"prompt": "Halo AI",
"n_predict": 50
}'Versi Lebih Advanced (Optional)
Kalau mau tuning performa:
command: >
-m /models/Llama-3.2-1B-Instruct-Q4_K_S.gguf
--ctx-size 1024
-b 256
-t 4
-ngl 0👉 Sekarang AI kamu bisa diakses lewat:
http://localhost:8080Integrasi ke Node.js
Contoh penggunaan:
// server.js - Minimal Express server that forwards to local llama.cpp API
import express from 'express';
import axios from 'axios';
const app = express();
app.use(express.json());
app.post('/api/chat', async (req, res) => {
const prompt = req.body.prompt ?? 'Halo AI';
try {
const resp = await axios.post('http://localhost:8080/completion', {
prompt,
n_predict: 128
});
res.json(resp.data);
} catch (err) {
res.status(500).json({ error: err.message });
}
});
app.listen(3000, () => console.log('Listening on http://localhost:3000'));Cara pakai singkat:
- Install deps
npm init -y && npm install express axios- Jalankan server
node server.js- Tes endpoint lokal
curl -X POST http://localhost:3000/api/chat \
-H "Content-Type: application/json" \
-d '{"prompt":"Halo AI"}'Catatan: endpoint internal llama.cpp bisa berbeda (/completion atau /v1/chat/completions). Sesuaikan URL axios jika merasa perlu.
Ini artinya:
-
kamu bisa bikin chatbot
-
integrasi ke backend
-
bahkan bikin produk AI sendiri
Contoh Use Case Nyata
1. IoT + ESP32
-
Kirim data suhu
-
AI analisis kondisi
2. Chatbot Kampus
-
Offline
-
Lebih hemat biaya
3. AI Lokal untuk Developer
- Testing tanpa API berbayar
⚡ Tips Optimasi llamacpp
Agar performa maksimal, gunakan parameter berikut:
-
-t→ jumlah CPU thread -
-ngl→ jumlah layer GPU -
-b→ batch size
Contoh:
-t 4 -ngl 0 -b 512Dampaknya:
-
Lebih cepat
-
Lebih efisien RAM
-
Lebih stabil
Kelebihan & Kekurangan
Kelebihan
-
Gratis & open-source
-
Bisa offline
-
Tidak butuh GPU
Kekurangan
-
Performa terbatas dibanding cloud
-
Setup awal butuh belajar
-
Tidak cocok untuk skala besar
Insight Penting
Banyak tools populer sebenarnya menggunakan llamacpp di belakang layar.
Artinya:
👉 kalau kamu paham llamacpp, kamu paham “mesin inti” AI lokal.
FAQ
Apa itu llamacpp?
llamacpp adalah tools untuk menjalankan AI secara lokal tanpa GPU.
Apakah llamacpp bisa offline?
Ya, sepenuhnya offline.
Apakah bisa digunakan di Node.js?
Bisa, menggunakan API server.
Apakah cocok untuk pemula?
Sangat cocok, terutama untuk belajar AI tanpa biaya mahal.
Apakah bisa digunakan untuk IoT?
Bisa, misalnya dengan ESP32 untuk analisis data sensor.
Penutup
Dengan llamacpp, AI tidak lagi eksklusif untuk perusahaan besar.
Sekarang kamu bisa:
-
menjalankan AI sendiri
-
membangun aplikasi pintar
-
bereksperimen tanpa batas
👉 Semua dari laptop kamu.